Version 1.1.1
1.1.1 Release
This release contributes significantly to the improvement “under the hood” with optimizations in the backend and in the source code. In addition to various performance improvements, various bugs have also been fixed. Furthermore, this release marks the introduction of AI functions in TESSA for the first time.
Automatic image recognition
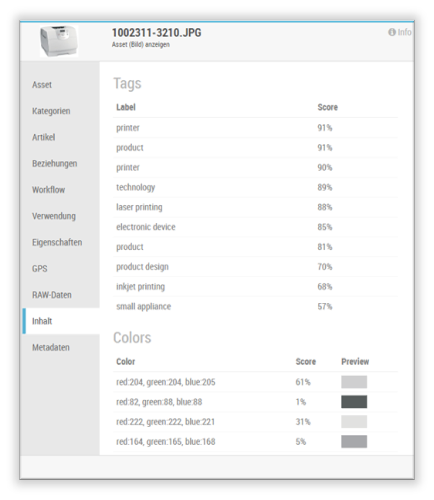
Thanks to the integration of new technologies, it is now possible to automatically recognize image content and provide this information to the user for assistance. For example, TESSA can use this information to make suggestions for keywords and categories or to automatically populate metadata.
OCR / text recognition
In addition to recognizing image content, text content in images can now also be identified. This can be text in scanned documents or product names in product photographs, for example. Any text that is recognized here can be used as required, e.g. when searching for product images.